Data Driven Learning
A peek behind the science and technology of Vocabulary.com
Vocabulary.com may seem simple on the outside, but behind the scenes we’re using sophisticated algorithms to help students learn over 17000 words more effectively.
How? We start with our massive pool of over 264.502,000 questions, and the millions of students who play Vocabulary.com every month. By comparing the answers of each student to the billions of answers given by other Vocabulary.com users, we can build computational models of each student’s vocabulary knowledge. We use these models to inform which words you learn, the pace at which you learn them, which questions you’ll see, and how often you’ll see them.
Reach Words - the words you’re ready to learn
It’d be easy for us to pick words you don’t know — we could simply pick the “hardest” words in the dictionary. What’s more useful is to predict words that you should know, but don’t.
Typically, these are words that are right on your word-learning horizon. Some of these words you may have encountered in reading or heard in class, but didn’t fully understand. Others, you might “kind of” know, but aren’t confident enough to use yourself in speaking or writing. We call these your “reach words”.

Try this: Visit a random word in our dictionary. In truth, our random word feature is not so random. Instead, we’re using our model of your word knowledge to show you a random word from your set of reach words. Words you might want to start learning! See a word you’d like to become more familiar with? Click the big green “Learn this word” button to add it to your personal learning program. But before you do, notice right above the button where it says “There’s a x% chance you know this word” — that sums up our model for you on this word in one easy-to-understand number. Under the hood things are a little more complicated.
What does it mean to really know a word?
Knowledge Value, Confidence and Recency
In reality, your knowledge of a word is based on many factors. First, there’s what we call your knowledge value — it represents how well you know a word. Your knowledge value for a word can be positive (we think you know it), or negative (we think you need help). Before you’ve answered a question on a word, your knowledge value is influenced by how you performed on similar words and how other students like you did on this word. Once you start learning a word, we use your performance to estimate your knowledge value.

We also measure our confidence in your knowledge value — which is how sure we are that you either know or don’t know a word. If, for example, you’ve gotten every question right (or wrong), we can be very confident in our assessment of your knowledge.
Finally, we add a time component to our model, which we call recency — it measures how long it’s been since you’ve given us input on this word. Over time, your knowledge level (and our confidence) will decay — which means it’s probably time for a brush-up question!
We use knowledge value, confidence, and recency to adjust the amount of time, or spacing, between repeated exposure to a word. The science of learning tells us that spaced repetition is one of the best ways to acquire and retain new information. Using the combination of these three factors, we can prioritize which words you need to learn and adjust the spacing between questions to maximize your retention.
Achieving Mastery
While knowledge value, confidence, and recency are very important to the learning process, they also can be hard to comprehend, since they model probabilities and change over time. That’s why we have mastery, which is a measure of how far you have progressed towards learning all the important meanings of a word. Many words (especially Tier II academic words) have multiple meanings. Because of this, we model each word by grouping related meanings. As you learn a word, you must demonstrate mastery on each group of meanings, starting from the core meaning of a word and progressing out to the peripheral meanings.
Your mastery of a word can never go down — it always progresses from 0 to 100% mastered. If you struggle with a word, you will need to answer more questions on that word — and it will take longer to master. Now you may be asking, is it possible to master a word and have a negative knowledge value? Absolutely! We still follow up after you finished mastering a word until you have a high knowledge value and we have a high confidence in your knowledge. Only once we’re certain you really know a word will we stop following up.
We learn by example — billions of examples, actually.

At Vocabulary.com our understanding of words begins with our corpus. What’s a corpus? It’s a monstrous collection of text that we’re adding to all the time. We feed our corpus daily with a balanced diet of news articles, novels, works of nonfiction, scholarly journals — all sorts of edited text. At last count, our corpus contained over 4 billion words!
Our corpus is the source of the millions of real-world example sentences in our dictionary, but we use it in other ways as well. In fact, having a healthy, growing corpus allows us to learn about the types of words that are likely to appear in different kinds of text, and analyze their relative frequencies. Our corpus data is an essential input to the algorithms that personalize learning, helping us to match players to words at their vocabulary level, and to select words that are appropriate to learn.
The problem with “yo-yo”

What does it mean to say a word is a “hard” word, or an “easy” word? Many vocabulary instruction programs use word frequency in a corpus to determine word difficulty. Unfortunately, corpus frequency doesn’t tell the full story. Consider the word yo-yo. Any first grader can tell you what a yo-yo is, but our corpus tells us that you’d expect to encounter yo-yo about once for every 38,375 pages of text. That puts it in the company of words like quotidian (38,127), ideograph (37,882), and actuarial (37,641) — all objectively much harder words.
How we model words, meanings and questions
Because of the wealth of data we have amassed, we can solve the “yo-yo” problem. First, we divide every word into groups of constituent meanings. Then we write questions that test each of the meanings using our ten different question types. By looking at how users respond to those questions, and by looking at how well those questions predict how you’ll do on other questions, we can compute the difficulty of each question, meaning and word very accurately.
A closer look at the word raise
Let’s look at the word raise as an example. Currently, we have 122 questions that test the 31 different meanings we have for raise. We group them into four groups that test:
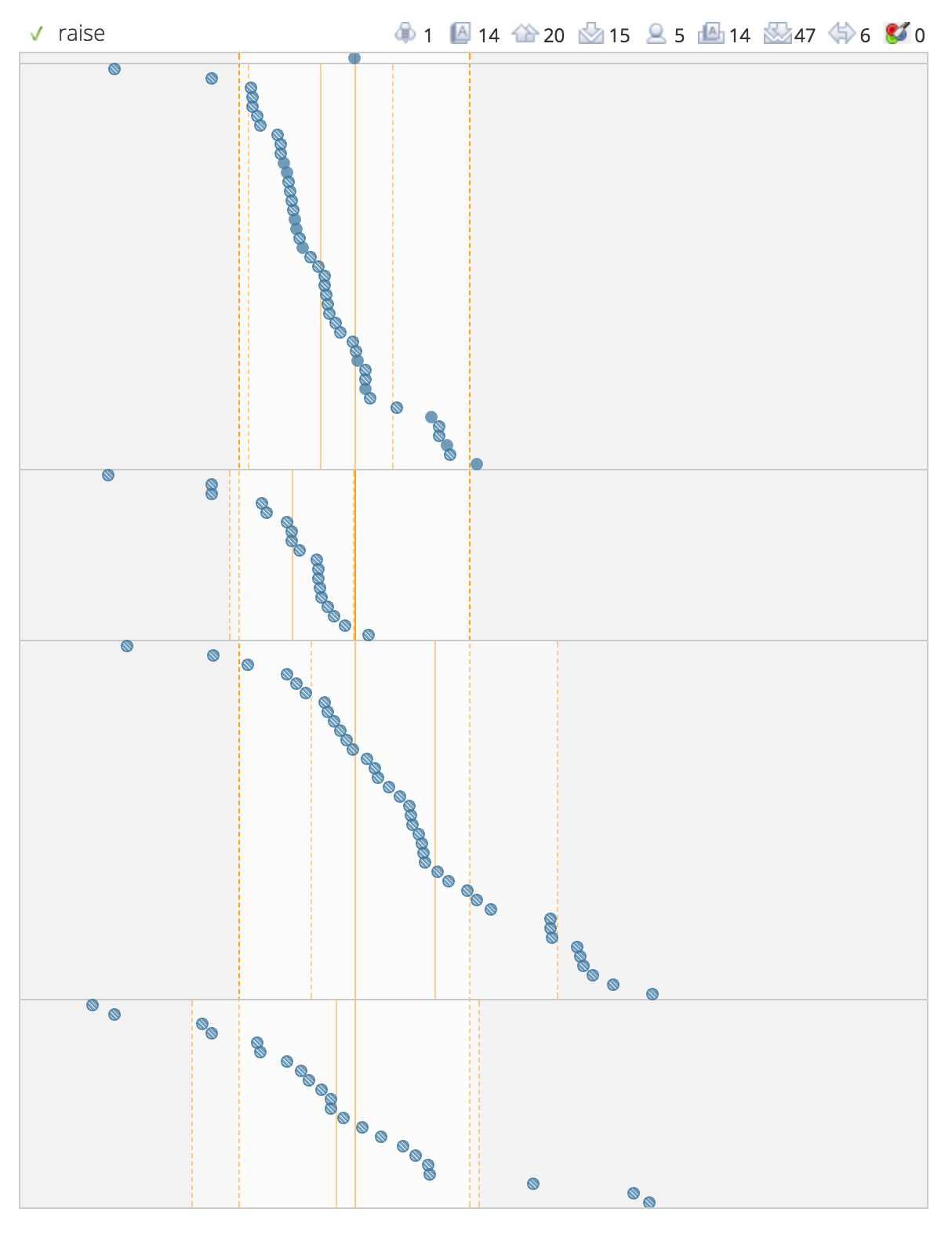
- Lifting, moving upwards (9 meanings - 6 verb, 3 noun)
- Increasing, promotion (10 meanings - 9 verb, 1 noun)
- Summon, call forth, stir-up (10 meanings - all verbs)
- Bring up, nurture, parent (2 meanings - all verbs)
You can see these questions plotted out in the chart on the right. Questions are depicted as circles, ordered from easiest on the left to hardest on the right. The various meaning groups are the horizontal stripes. You can easily see two things from this graph: 1) not all the meanings of raise are the same difficulty, and 2) even within one meaning group, there are a range of difficulty of questions.
No one student will see all 122 questions on raise. Instead, we will pick questions that are appropriate for each user. Students who need a little more help will see questions that are a little easier and provide more scaffolding. Students with a more advanced knowledge of this word will see harder questions that may test some of the subtler nuances of appropriate usage, for example.
We use all the answers we receive to help us learn about both the questions and the students answering them. From all the answer data, we can build statistical models that try to predict how both each question and each student is going to perform.
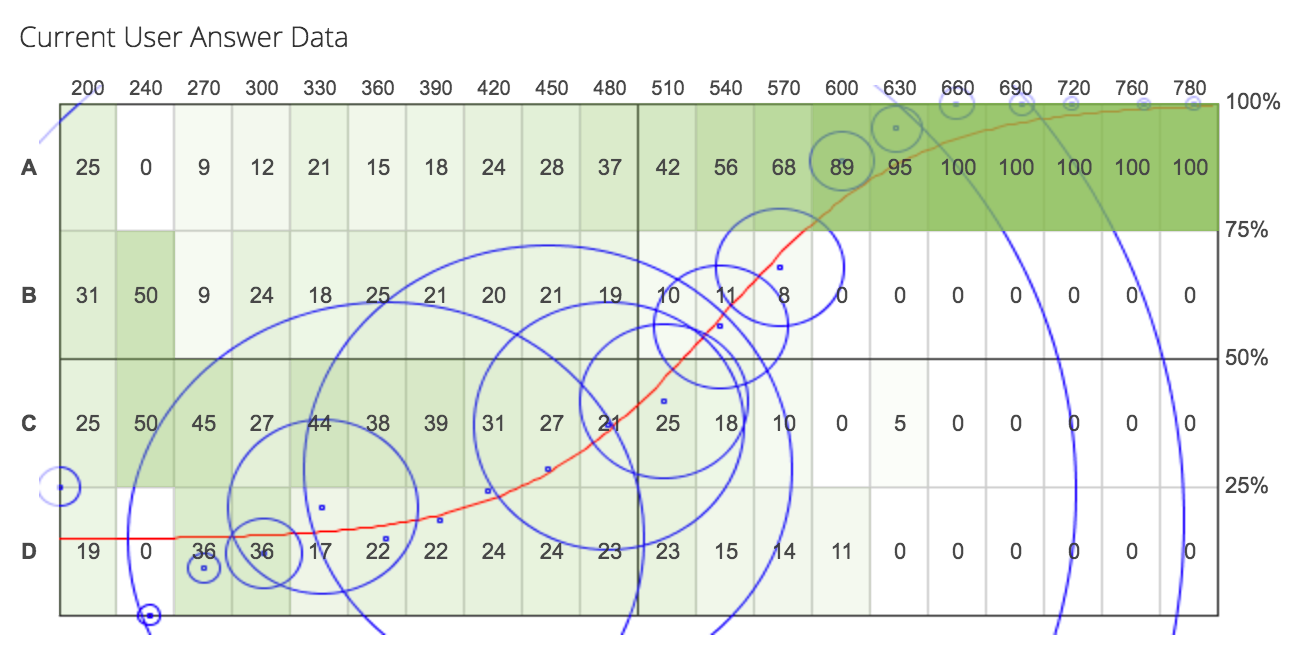

To the right is a graph showing an overview of one of the models we have for a question on raise. In this graph, the red line shows how we expect the question to perform. For the purposes of this display, user data is grouped and arranged horizontally by SAT-style score bands from 200 to 800. The blue circles represent actual user data. The bigger the circle, the more students in that band answered this question. The right y-axis represents the probability that a user in any band answered the question correctly. The left y-axis displays the 4 answer choices of the question (A is always correct). The numbers in each rectangle show the probability that someone in that score band would choose this answer.
We can tell a lot from this one display. First, we can see that this question is performing well because you can see that as user ability level increases, the probability they’ll get this question correct increases. Also, the user data (the dots at the centers of the circles) is fitting our predictive curve quite well. You can also see that answers B, C, & D are performing roughly equally as distractors.
The difficulty of the question is determined by the score at the point where the red line crosses the x-axis. The discrimination (how well this question predicts your ability) is determined by the slope of the line at the x-intercept. The steeper the slope, the better predictor this question is.
Questions that do not fit the model, or negatively discriminate are re-reviewed by our editors for accuracy, cultural bias, or other issues.
Every day, we re-integrate the models for each question and player so that our models become more accurate over time. To date, we have reviewed over 150,000 data points on this question alone!
We hope you’ve enjoyed this whirlwind tour of some of the science and technology behind Vocabulary.com. Want to learn even more about the science behind our data-driven approach to word learning? The Vocabulary.com white paper lays out how Vocabulary.com harnesses big data to bring insights from the science of learning into practical use for teachers and students.
See your students learning.
Discover a better way to teach vocabulary.
Learn about our premium subscription