The word algorithm, in the sense most frequently used today, is not old in English — it dates from the 20th century — but its origins go back more than a thousand years before that: it's an eponym based on the name of the Arab mathematician Abū 'Abdallāh Muḥammad ibn Mūsā al-Khwārizmī, known for his many contributions to mathematics. The rise in frequency of the word algorithm coincides with the advent of the computer age. Starting in the mid-1950s, people have found more and more reasons to talk about, write about, and use algorithms, as this graph from Google Ngrams shows:
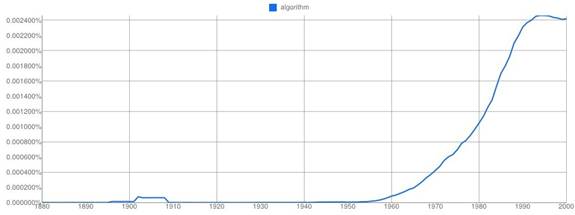
In its broadest meaning — a step-by-step procedure for solving a problem or achieving an end — algorithms are even older than the great mathematician for whom they are named. Even animals perform algorithms, if you include in the concept a repeatable sequence of behaviors aimed at achieving a result. The computer's ability to multiply the length, complexity, and variability of algorithms, and to execute them with astonishing speed and unfailing accuracy, are what give algorithms the power and range of applications that they enjoy today.
Language, especially written language, lends itself to treatment by algorithms because it is a rule-driven symbolic system: its tokens displays meaningful patterns that can be analyzed and manipulated. Teach a computer to recognize some rules about language, develop algorithms for computers to apply to big buckets of text, and before you know it, computers may be able to tell you things about language or extracted from language that you didn't know before, or that the writer didn't suspect he or she was revealing. Algorithms work at multiple levels to do things with words: from the spell-checking that we now all take for granted to the auto-complete features of cell phones that try to predict what we're trying to type. More sophisticated applications use multiply-nested algorithms to perform such tasks as summarization and question answering. Whether simple or complex, the basis of most algorithmic manipulation of language — or natural language processing (NLP), as the field is called — is to assign probabilities to patterns that computers encounter in language with the aim of making those assignments an accurate reflection of the way people encode and decode meaning in language. At present, this is at best a very clunky approximation of the speed, accuracy, and fluency with which the human mind processes language.
The opportunity to derive useful information at low cost from a resource that is itself free — written language online — has resulted in a bonanza for the algorithmically inclined. It's probably safe to say there's nothing you type online that will not be subject to algorithmic manipulation at some point. If you're using a search engine, algorithms grab your search string the instant you hit "Enter" or click on an appropriate icon. While some algorithms fetch suitable results for you to peruse, others decide what ads to show you alongside these results. But other algorithms are quietly at work 24/7, sifting through your Tweets, your status updates, the reviews of businesses and services that you put online, your blog posts, and in many cases your emails. What are all these algorithms doing, and should you care?
A popular application of NLP today is called sentiment extraction: the use of algorithms to extract what people think and feel about their experiences. Sentiment extraction can be applied to what people write about restaurants, resorts, books, professionals offering services, and anything else for which they might exchange money. We are now all able to take advantage of seeing what others think first before we buy or book something online and to do this we can read several reviews, or look at a star-coded summary of reviews. Computers go a step further and read through dozens or hundreds of reviews to build up a profile of a particular product, business, or service, like this:
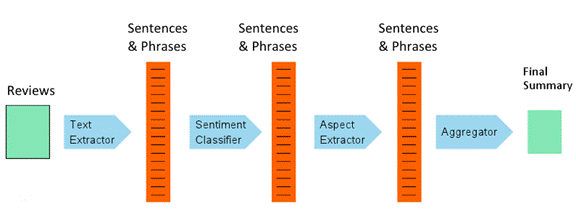
adapted from "Building a Sentiment Summarizer for Local Service Reviews" by Sasha Blair-Goldensohn
Algorithms first extract text in which evaluative words are used; these are then sorted into a scale of values from very bad (words like abysmal, deplorable, sucked, etc.) to very good (fantastic, splendid, awesome). Aspects of the experience being reviewed are also extracted (e.g., the food, service, ambience, noise, etc. in a restaurant) and these are matched up with the evaluative words applied to them. Finally, other algorithms make a statistical evaluation of the earlier algorithms' findings to arrive at a summary.
Does it work? It works well enough that businesses now feel the need to monitor and curate what people say about them online, and companies have emerged that claim to be able to handle damage control in this area. Reputation.com, currently the most visible of such companies, invites you on its website to "Call the most experienced reputation advisors in the business and we'll replace your inaccurate or misleading search results with new, truthful, accurate results." You wonder how this would work. What if the negative search results are in fact the only thing out there, and an accurate reflection of what you do or provide? Suppose all the trash talk about you has already been collated and summarized by numerous algorithmic operations before the "experienced reputation advisors" even get their tools out? Well, it turns out that Reputation.com has an algorithm for that. They say on their website: "Reputation.com implements a complex algorithm that redirects Google's search engine, pushing the information you don't want others to see beneath positive, accurate search results." All hail the power of the algorithm.
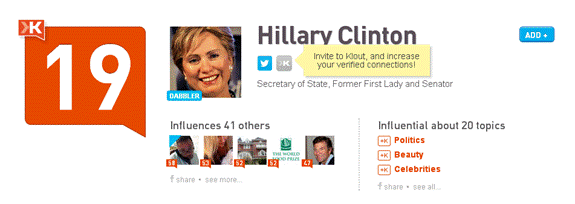
Another company that's all about algorithms is Klout, which calls itself "The Standard of influence" and purports to rank people, companies, and other entities according to the amount of influence they have on others. Algorithm occurs nearly 700 times on Klout's website, mostly on background pages and FAQs in which the company explains the wonders of its work in arriving at its signature product, the Klout score: a numeric between 1 and 100 that represents how influential Klout thinks you are.
The Twitter account "Big Ben" tweets the word bong (or multiples of it) every hour on the hour, at the same time that the landmark clock of the same name strikes the hour. For this modest entertainment, and as a result of Klout's proprietary algorithms, Big Ben gets a whopping Klout score of 75 for the influence it has on people. Big Ben (the Tweeter, not the clock), according to Klout, is a "Thought Leader" and vastly more influential than Hillary Clinton (a Dabbler), who has a Klout score of only 19.

The complexity of language, combined with the natural facility that humans enjoy in using it, suggests that the application of algorithms to language is still in its infancy. For now, it's probably helpful to keep in mind that anything you say online can be used — certainly will be used — as algorithm fodder. It will probably not be used against you, but it may be used in ways that you might never have imagined. It also seems that for now, a cartload of smoke and mirrors can lurk behind the word algorithm.
